问题:75% 的公司禁止使用 ChatGPT
尽管对像 ChatGPT 这样的生成式 AI 工具最初充满热情,但由于日益增长的数据隐私和网络安全担忧,公司正在限制其使用。主要担忧是这些 AI 工具会存储和学习用户数据,可能导致意外的数据泄露。尽管 ChatGPT 的开发商 OpenAI 提供了选择退出用于训练用户数据的功能,但系统内的数据处理方式仍然不明确。此外,关于 AI 导致的数据泄露的责任的明确法律法规也缺乏。因此,公司犹豫不决,正在等待技术和监管的进一步发展。
微软已警告其员工不要与 ChatGPT 分享敏感数据,该聊天机器人由 OpenAI 开发 来源 。人们担心机密信息可能会意外地与聊天机器人共享,进而可能传播给其他用户。鉴于该公司与 OpenAI 的合作和投资,微软的谨慎态度值得关注。亚马逊也向其员工发出了类似的警告。保护机密数据的责任仍不明确,需要更清晰的指导方针和法规来应对这种情况。OpenAI 的服务条款允许该公司使用用户和 ChatGPT 生成的所有输入和输出,尽管计划删除个人数据。然而,人们仍然担心通过精心设计的输入提示提取私有公司数据。
解決方案:自托管 AI 模型
解决围绕 AI 模型的数据安全和隐私问题的方法是将这些模型托管在自己服务器上。这使得公司能够控制其数据,并确保数据不会落入不法之手。自托管 AI 模型提供了一种安全可靠的方式来使用 AI 技术,无需担心数据隐私和网络安全问题。
我们将使用 Ollama 和 Chatbox。Ollama 是一个简化的工具,用于在本地运行开源大语言模型 (LLM),例如 Mistral 和 Llama 2。Chatbox 是一款可视化各种模型 API 调用的应用程序。
这听起来过于繁琐吗?或者托管 API 会更好?请访问 document-chat.com 或 与我们安排免费的介绍性通话 。
第 1 步:Ollama 下载和安装
您需要一台配备 GPU 的服务器或计算机。不幸的是,这必须是至少具有 8GB VRAM 的 NVIDIA GPU,或具有 M 系列芯片的 Apple Mac。 可在以下文章中找到确切要求:自托管 AI 模型的优势是什么?
简而言之:
- https://ollama.com/download
ollama run llama2- 可在 localhost:11434 访问 ollama
Ollama 是什么?
Ollama 是一个简化的工具,用于在本地运行开源大语言模型 (LLM),例如 Mistral 和 Llama 2。Ollama 将模型权重、配置和数据集打包到一个由模型文件管理的单一实体中。
这听起来过于繁琐吗?或者托管 API 会更好?请访问 document-chat.com 或 与我们安排免费的介绍性通话 。
Ollama 支持各种 LLM,包括 LLaMA-2、无审查 LLaMA、CodeLLaMA、Falcon、Mistral、Vicuna、WizardCoder 和 Wizard 无审查版。
Ollama 支持多种模型,包括 Llama 2、Code Llama 等。它将模型权重、配置和数据打包到一个由模型文件定义的单个单元中。
Ollama 上五个最受欢迎的模型是:
- llama2:最受欢迎的通用模型。
- mistral:Mistral AI 的 7B 模型,更新到 0.2 版。
- codellama:一个大型语言模型,使用文本输入生成和讨论代码。
- dolphin-mixtral:一个基于 Mixtral MoE 的无审查、微调模型,特别适合编码任务。
- mistral-openorca:使用 OpenOrca 数据集微调的 Mistral 7b。
Ollama 还支持自定义模型。您可以使用模型文件创建模型,指定层、编写权重并收到成功消息。
其他可用模型包括:
- Llama2:Meta 的基础“开源”模型。
- Mistral/Mixtral:在 Mistral 7B 模型上使用 OpenOrca 数据集微调的 70 亿参数模型。
- LLaVA:一种多模态模型(大型语言和视觉助手),能够解释视觉输入。
- CodeLlama:在英语代码和自然语言上训练的模型。
- DeepSeek Coder:在英语 87% 的代码和 13% 的自然语言上训练。
- Meditron:从 Llama 2 调整到医疗领域的开源医疗模型。
Ollama 的安装和设置
- 从官方网站下载 Ollama。
- 安装过程类似于其他软件。对于 macOS 和 Linux,使用
curl https://ollama.ai/install.sh | sh。 - Ollama 创建一个 API 用于与本地模型交互。
- Ollama 与 macOS 和 Linux 兼容;Windows 支持即将推出。
使用 Ollama 运行模型
运行模型非常简单。下载模型并使用终端中的“run”命令执行它们。如果未安装模型,Ollama 会自动下载它。例如,使用“ollama run codellama”运行 CodeLlama。
模型保存在 ~/.ollama/models 目录中。通过“ollama pull”下载模型时,它存储在 ~/.ollama/models/manifests/registry.ollama.ai/library/<模型系列>/latest 中。
Ollama 还提供 REST API 访问以进行实时交互。
其他功能
Ollama 支持导入 GGUF 和 GGML 模型文件,从而允许模型创建、迭代和共享。
可用模型
可在 Ollama 模型库页面找到可用模型列表。
总之,Ollama 为在本地运行 LLM 提供了一个用户友好的平台。它对开发人员、研究人员和 AI 爱好者来说是一个宝贵的资源。
第 2 步:使用 Chatbox GUI 控制和使用 Ollama
Chatbox 是一款可视化各种模型 API 调用的应用程序。
Chatbox 安装
访问 https://chatboxai.app 并将应用程序安装到您的计算机上。
连接 Chatbox 和 Ollama
我们的本地 AI 模型在 localhost:11434 可访问。Chatbox 允许轻松与 Ollama 交互。单击“设置”并选择 Ollama 作为“AI 模型提供商”。
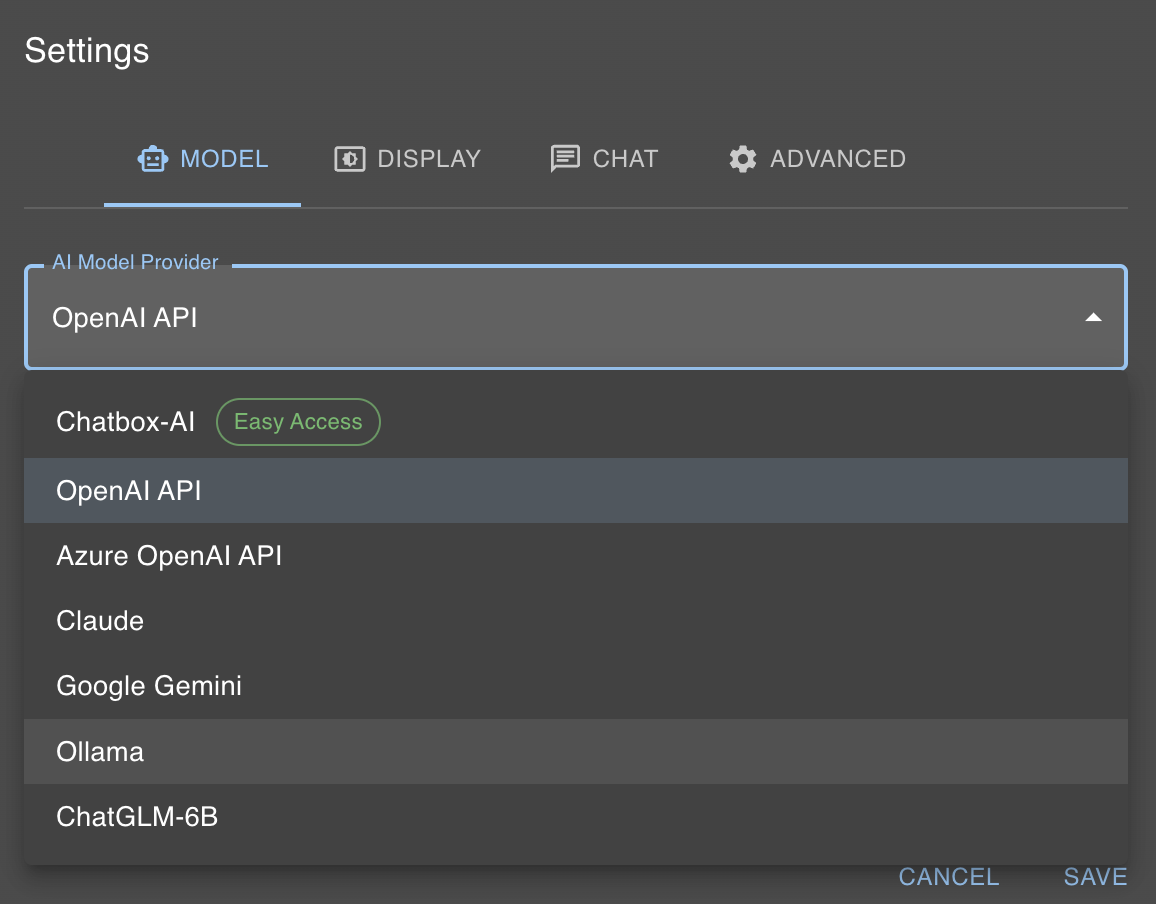
然后,从模型对话框中选择所需的模型(例如 llama2)。
这听起来过于繁琐吗?或者托管 API 会更好?请访问 document-chat.com 或 与我们安排免费的介绍性通话 。