Le problème : 75 % des entreprises interdisent l’utilisation de ChatGPT
Malgré l’enthousiasme initial suscité par les outils d’IA générative tels que ChatGPT, les entreprises envisagent de restreindre leur utilisation en raison de préoccupations croissantes concernant la confidentialité des données et la sécurité informatique. La principale inquiétude réside dans le fait que ces outils d’IA stockent et apprennent à partir des données des utilisateurs, ce qui pourrait potentiellement entraîner des fuites de données non intentionnelles. Bien qu’OpenAI, le développeur de ChatGPT, propose une option de désactivation pour l’entraînement avec les données des utilisateurs, la manière dont les données sont traitées au sein du système reste incertaine. De plus, il n’existe pas de réglementations claires concernant la responsabilité en cas de violation de données causée par l’IA. Par conséquent, les entreprises sont de plus en plus prudentes et attendent de voir comment la technologie et sa réglementation évoluent.
Microsoft a mis en garde ses employés contre le partage de données sensibles avec ChatGPT, le chatbot développé par OpenAI Source . La crainte est que des informations confidentielles puissent être partagées accidentellement avec le chatbot, qui pourrait ensuite les partager avec d’autres utilisateurs. L’approche prudente de Microsoft est remarquable étant donné que l’entreprise a conclu un partenariat avec OpenAI et y a investi. Amazon a également publié un avertissement similaire à ses employés. La responsabilité de la protection des données confidentielles est actuellement floue, et il existe un besoin de directives et de réglementations plus claires pour ces situations. Les conditions d’utilisation d’OpenAI permettent à l’entreprise d’utiliser toutes les entrées et sorties générées par les utilisateurs et ChatGPT, tout en devant supprimer les données personnelles. Cependant, des préoccupations persistent quant à la possibilité d’extraire des données d’entreprise privées grâce à des invites habilement formulées.
La solution : Des modèles d’IA hébergés en interne
Une solution aux préoccupations relatives à la sécurité et à la confidentialité des données lors de l’utilisation de modèles d’IA consiste à héberger ces modèles en interne. Cela permet aux entreprises de conserver le contrôle de leurs données et de garantir qu’elles ne tombent pas entre de mauvaises mains. Les modèles d’IA hébergés en interne offrent une manière sécurisée et fiable d’utiliser la technologie d’IA sans avoir à s’inquiéter des préoccupations relatives à la confidentialité et à la sécurité informatique.
Nous allons utiliser Ollama et Chatbox. Ollama est un outil optimisé pour l’exécution locale de modèles linguistiques importants (LLM) open source comme Mistral et Llama 2. Chatbox est une application qui permet de visualiser les appels API vers différents modèles.
Cela vous semble trop compliqué ? Ou préférez-vous une API hébergée ? Utilisez document-chat.com ou prenez rendez-vous pour une discussion gratuite .
Étape 1 : Téléchargement et installation d’Ollama
Vous avez besoin d’un serveur ou d’un ordinateur doté d’une carte graphique. Malheureusement, il doit s’agir d’une carte graphique NVidia avec au moins 8 Go de VRAM, ou d’un Macbook avec une puce M-série. Vous trouverez les exigences précises dans le post : Quels sont les avantages des modèles d’IA hébergés en interne ?
Version TLDR :
- https://ollama.com/download
ollama run llama2- Ollama est accessible sous localhost:11434
Qu’est-ce qu’Ollama ?
Ollama est un outil optimisé pour l’exécution locale de modèles linguistiques importants (LLM) open source comme Mistral et Llama 2. Ollama regroupe les poids du modèle, les configurations et les ensembles de données en une seule entité gérée par un fichier modèle.
Cela vous semble trop compliqué ? Ou préférez-vous une API hébergée ? Utilisez document-chat.com ou prenez rendez-vous pour une discussion gratuite .
Ollama prend en charge différents LLM, notamment LLaMA-2, LLaMA non censuré, CodeLLaMA, Falcon, Mistral, le modèle Vicuna, WizardCoder et Wizard non censuré.
Ollama prend en charge une variété de modèles, dont Llama 2, Code Llama et d’autres. Il regroupe les poids du modèle, les configurations et les données en une seule unité définie par un fichier modèle.
Les cinq modèles les plus populaires sur Ollama sont :
- llama2 : Le modèle le plus populaire pour une utilisation générale.
- mistral : Le modèle 7 B de Mistral AI, mis à jour vers la version 0.2.
- codellama : Un grand modèle linguistique qui utilise des entrées textuelles pour générer et discuter de code.
- dolphin-mixtral : Un modèle non censuré, affiné sur la base du modèle Mixtral MoE, particulièrement adapté aux tâches de codage.
- mistral-openorca : Mistral 7 B, affiné avec l’ensemble de données OpenOrca.
Ollama prend également en charge la création et l’utilisation de modèles personnalisés. Vous pouvez créer un modèle à l’aide d’un fichier modèle, en fournissant le fichier modèle, en créant différentes couches, en écrivant les poids et en recevant finalement un message de réussite.
Certains autres modèles disponibles sur Ollama incluent :
- Llama2 : Le modèle “open source” de base de Meta
- Mistral/Mixtral : Un modèle de 7 milliards de paramètres, affiné sur le modèle Mistral 7 B avec l’ensemble de données OpenOrca.
- Llava : Un modèle multimodal appelé LLaVA (Large Language and Vision Assistant), capable d’interpréter les entrées visuelles.
- CodeLlama : Un modèle entraîné à la fois sur le code et sur le langage naturel en anglais.
- DeepSeek Coder : Entraîné à partir de zéro sur 87 % de code et 13 % de langage naturel en anglais.
- Meditron : Un modèle médical open source, adapté à partir de Llama 2 au domaine médical.
Installation et configuration d’Ollama
- Téléchargez Ollama depuis le site officiel.
- Le processus d’installation est simple et similaire à celui d’autres logiciels. Pour les utilisateurs macOS et Linux, Ollama peut être installé avec une commande : curl https://ollama.ai/install.sh | sh.
- Une fois Ollama installé, il crée une API permettant au modèle d’être fourni, permettant aux utilisateurs d’interagir directement avec le modèle à partir de leur ordinateur local.
- Ollama est compatible avec macOS et Linux ; la prise en charge de Windows sera disponible prochainement. Il peut être facilement installé et utilisé pour exécuter différents modèles open source localement. Vous pouvez sélectionner le modèle souhaité dans la bibliothèque Ollama.
Exécution des modèles avec Ollama
L’exécution des modèles avec Ollama est un processus simple. Les utilisateurs peuvent télécharger les modèles et les exécuter avec la commande “run” dans l’application de terminal. Si le modèle n’est pas installé, Ollama le télécharge automatiquement. Par exemple, pour exécuter le modèle CodeLlama, utilisez la commande “ollama run codellama”.
Les modèles sont stockés dans le répertoire ~/.ollama/models-structure sur votre ordinateur local. Lorsque vous téléchargez un modèle avec la commande “ollama pull”, il est stocké dans le répertoire ~/.ollama/models/manifests/registry.ollama.ai/library/<famille_de_modèles>/latest.
Ollama prend également en charge l’utilisation du modèle via une API REST pour des interactions en temps réel.
Fonctionnalités supplémentaires
L’une des fonctionnalités uniques d’Ollama est la prise en charge de l’importation des formats de fichier GGUF et GGML dans le fichier modèle. Cela signifie que vous pouvez créer un modèle, le développer, l’améliorer de manière itérative et le télécharger pour le partager avec d’autres lorsque vous êtes prêt.
Modèles disponibles
Ollama prend en charge une variété de modèles. Vous trouverez une liste des modèles disponibles sur la page de la bibliothèque de modèles Ollama.
En résumé, Ollama offre un environnement convivial pour l’exécution locale des modèles linguistiques importants. C’est un outil puissant pour les développeurs, les chercheurs et les passionnés d’IA pour exploiter les potentialités des LLM.
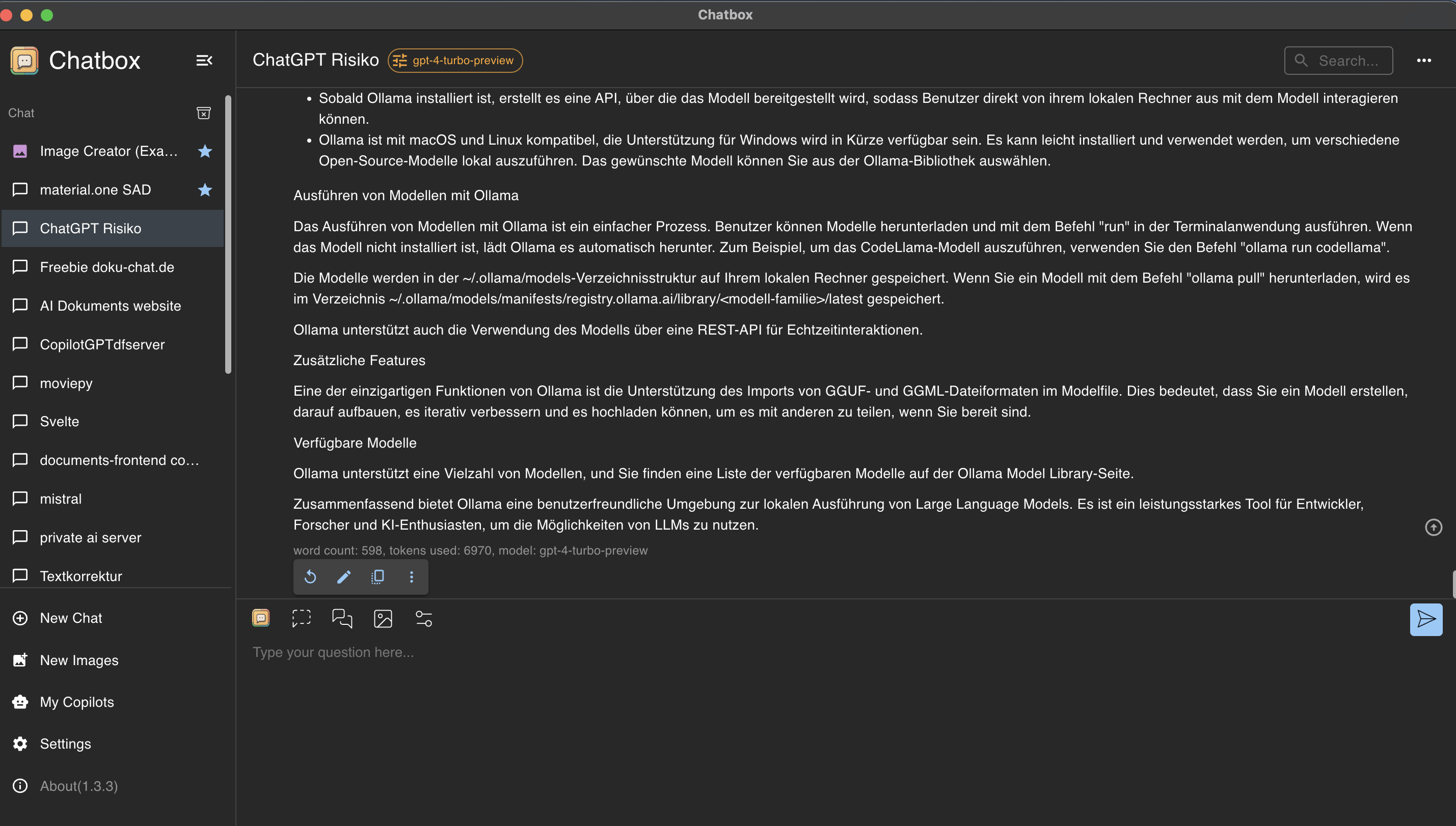
Étape 2 : Contrôler et utiliser Ollama avec l’interface utilisateur Chatbox
Chatbox est une application qui permet de visualiser les appels API vers différents modèles.
Installation de Chatbox
Visitez https://chatboxai.app et installez l’application sur votre ordinateur.
Connexion de Chatbox et d’Ollama
Comme mentionné précédemment, notre modèle d’IA local est désormais accessible via localhost:11434. Chatbox offre heureusement un moyen simple d’interagir avec Ollama. Pour ce faire, cliquez sur “Paramètres” et sélectionnez “Fournisseur de modèle d’IA” Ollama.
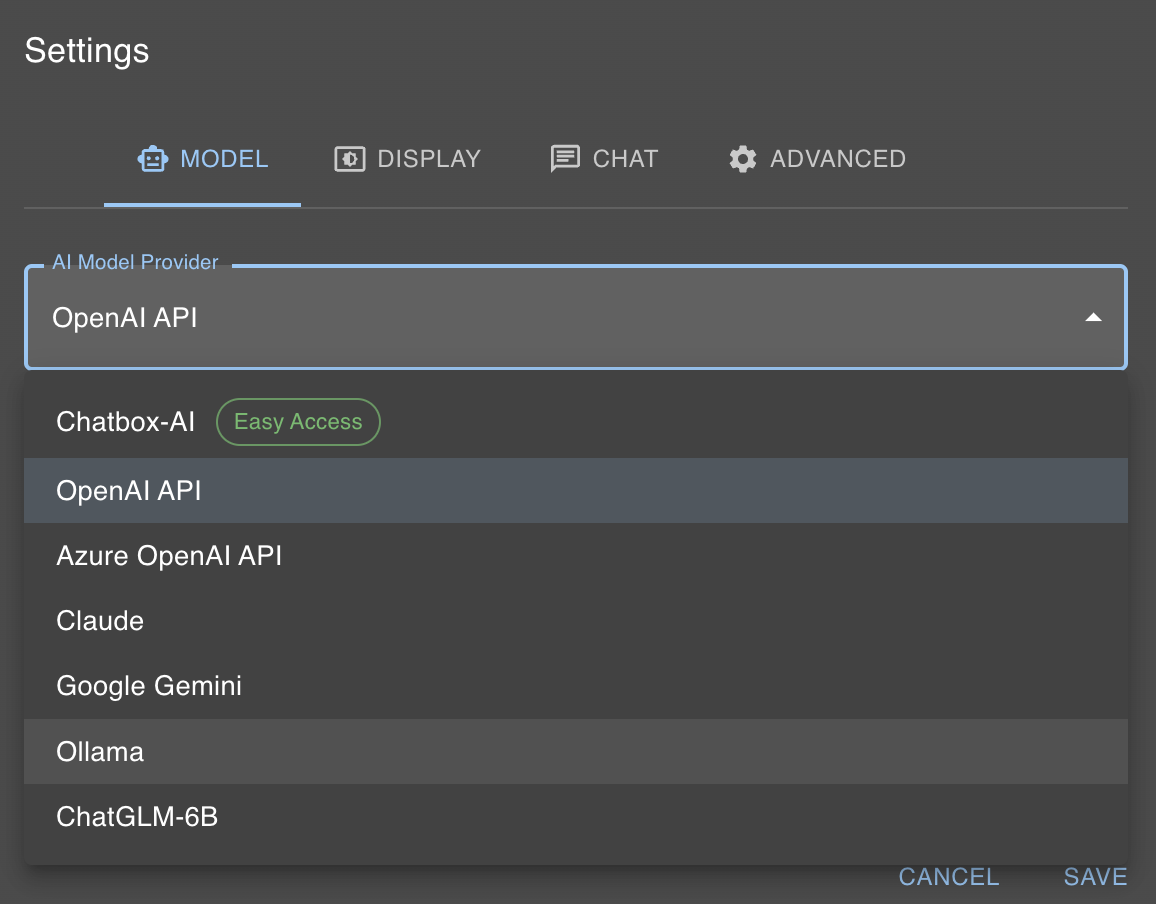
Ensuite, il suffit de sélectionner le modèle dans la boîte de dialogue du modèle que vous avez choisi avec la commande ollama run, dans notre cas llama2.
Cela vous semble trop compliqué ? Ou préférez-vous une API hébergée ? Utilisez document-chat.com ou prenez rendez-vous pour une discussion gratuite .