Trouver une source de connaissance
Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat sed.
Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat sed.
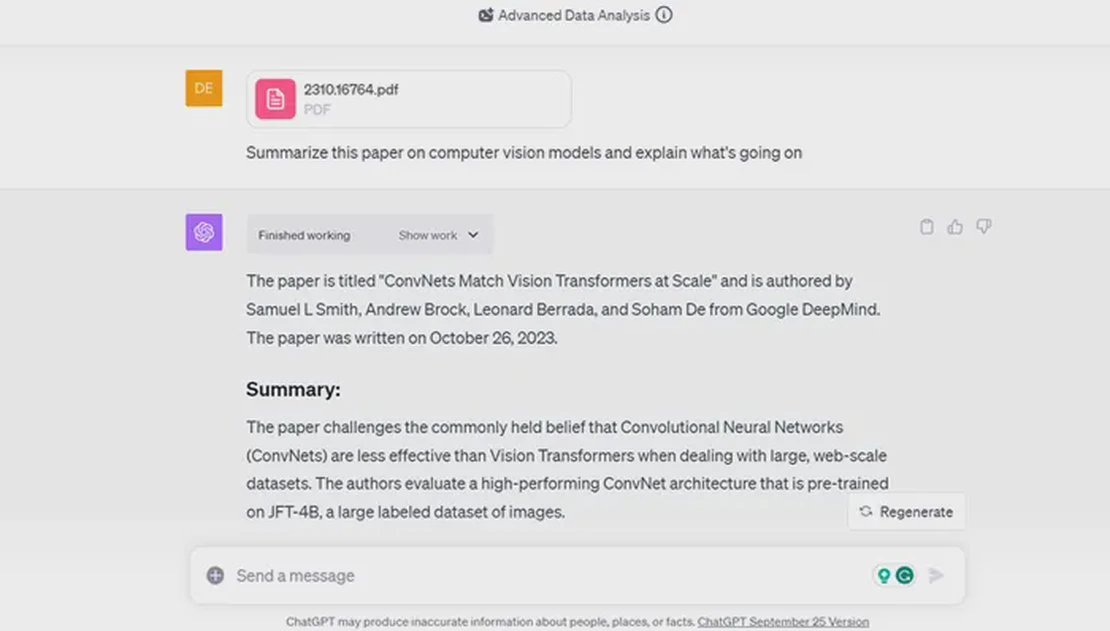
Les modèles linguistiques avancés comme ChatGPT possèdent des capacités impressionnantes en matière de génération de texte semblable à celui humain et de réponse aux questions. Cependant, il est important de comprendre que ces modèles ne possèdent qu’une connaissance générale et n’ont pas accès à des informations contextuelles spécifiques. De plus, ils sont souvent basés sur des connaissances plus anciennes, ce qui signifie qu’ils peuvent ne pas disposer des informations les plus récentes.
Les modèles linguistiques avancés comme ChatGPT possèdent indéniablement d’impressionnantes capacités à générer du texte de type humain et à répondre aux questions. Cependant, il est crucial de comprendre que ces modèles s’appuient sur des connaissances générales et n’ont pas accès à des informations contextuelles spécifiques. De plus, ils fonctionnent souvent avec des bases de connaissances plus anciennes, ce qui signifie qu’ils peuvent ne pas avoir accès aux dernières informations.

Les grands modèles linguistiques comme GPT (Generative Pre-trained Transformer) sont devenus des outils puissants pour un large éventail d’applications dans le monde de l’intelligence artificielle (IA). Cependant, les entreprises doivent faire preuve de prudence quant à une dépendance excessive à ces modèles. Bien qu’ils offrent précision et évolutivité, ils présentent également des limites. Ils peuvent produire des réponses biaisées ou incorrectes en raison des limites de leurs données d’entraînement, et ils ne sont pas capables de comprendre pleinement le contexte et les nuances humaines.
Dans le monde de l’intelligence artificielle (IA), les grands modèles linguistiques tels que GPT (Generative Pre-trained Transformer) se sont imposés comme des outils puissants pour une multitude d’applications. Cependant, les entreprises doivent faire preuve de prudence en s’appuyant trop lourdement sur ces modèles. Bien qu’ils offrent précision et évolutivité, ils ont aussi leurs limites. Ils peuvent produire des réponses biaisées ou erronées en raison des limitations des données d’entraînement et ne sont pas capables de comprendre pleinement le contexte humain et les subtilités.
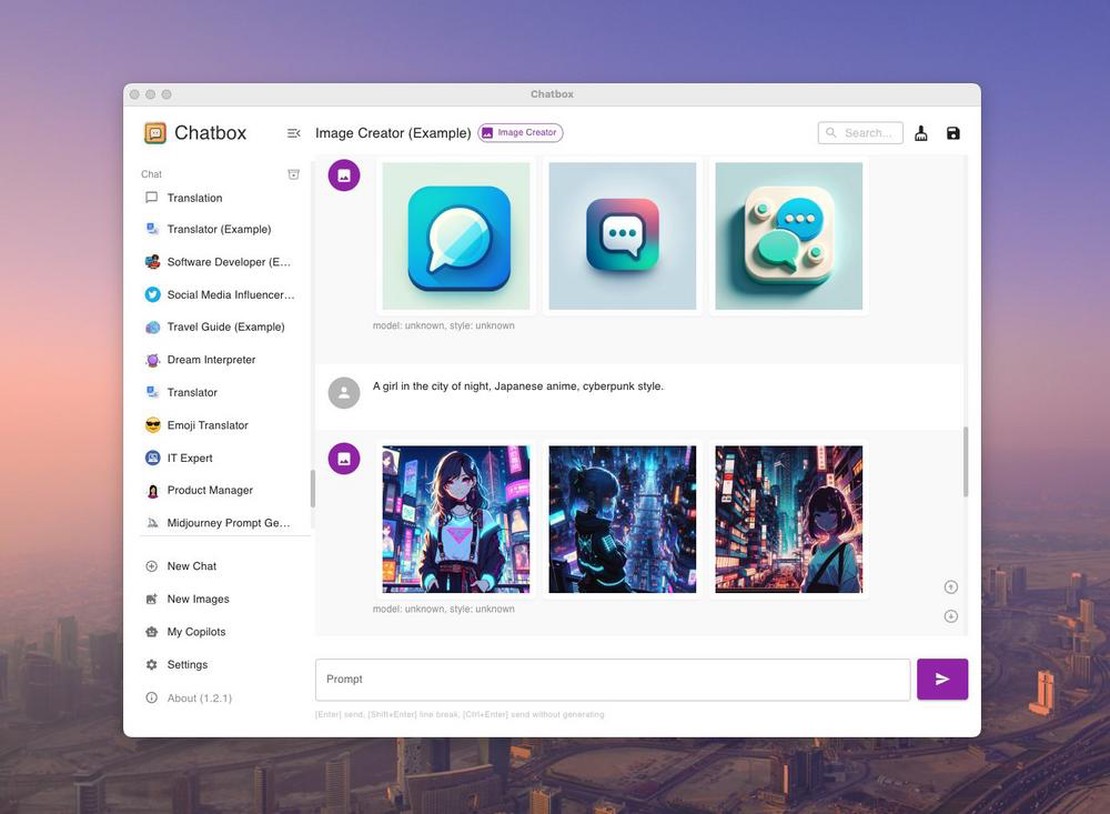
Malgré l’enthousiasme initial suscité par les outils d’IA générative comme ChatGPT, les entreprises restreignent leur utilisation en raison des préoccupations croissantes concernant la confidentialité des données et la cybersécurité. La principale inquiétude est que ces outils d’IA stockent et apprennent à partir des données utilisateur, ce qui pourrait entraîner des violations de données non intentionnelles. Bien qu’OpenAI, le développeur de ChatGPT, propose une option de désinscription de la formation avec les données utilisateur, la gestion des données au sein du système reste imprécise. De plus, il manque de réglementations juridiques claires concernant la responsabilité des violations de données causées par l’IA. Par conséquent, les entreprises hésitent et attendent que la technologie et sa réglementation évoluent.
Malgré l’enthousiasme initial suscité par les outils d’IA générative tels que ChatGPT, les entreprises envisagent de restreindre leur utilisation en raison de préoccupations croissantes concernant la confidentialité des données et la sécurité informatique. La principale inquiétude réside dans le fait que ces outils d’IA stockent et apprennent à partir des données des utilisateurs, ce qui pourrait potentiellement entraîner des fuites de données non intentionnelles. Bien qu’OpenAI, le développeur de ChatGPT, propose une option de désactivation pour l’entraînement avec les données des utilisateurs, la manière dont les données sont traitées au sein du système reste incertaine. De plus, il n’existe pas de réglementations claires concernant la responsabilité en cas de violation de données causée par l’IA. Par conséquent, les entreprises sont de plus en plus prudentes et attendent de voir comment la technologie et sa réglementation évoluent.