Das Problem: 75% der Unternehmen verbieten die Nutzung von ChatGPT
Trotz der anfänglichen Begeisterung für generative KI-Tools wie ChatGPT ziehen Unternehmen aufgrund wachsender Datenschutz- und Cybersicherheitsbedenken in Erwägung, deren Verwendung einzuschränken. Die Sorge besteht vor allem darin, dass diese KI-Tools Nutzerdaten speichern und aus ihnen lernen, was potenziell zu unbeabsichtigten Datenlecks führen könnte. Obwohl OpenAI, der Entwickler von ChatGPT, eine Opt-out-Option für das Training mit Nutzerdaten bietet, bleibt die Frage, wie die Daten innerhalb des Systems gehandhabt werden, unklar. Zudem fehlen klare gesetzliche Regelungen zur Verantwortung bei durch KI verursachten Datenverletzungen. Unternehmen sind daher zunehmend vorsichtig und warten ab, wie sich die Technologie und ihre Regulierung weiterentwickeln.
Microsoft hat seine Mitarbeiter davor gewarnt, sensible Daten mit ChatGPT, dem von OpenAI entwickelten Chatbot, zu teilen Quelle . Die Sorge ist, dass vertrauliche Informationen versehentlich mit dem Chatbot geteilt werden könnten, der diese Informationen dann möglicherweise mit anderen Nutzern teilen könnte. Microsofts vorsichtiger Ansatz ist bemerkenswert, wenn man bedenkt, dass das Unternehmen eine Partnerschaft mit OpenAI eingegangen ist und in diese investiert hat. Auch Amazon hat eine ähnliche Warnung an seine Mitarbeiter herausgegeben. Die Verantwortung für den Schutz vertraulicher Daten ist derzeit unklar, und es besteht ein Bedarf an klareren Richtlinien und Vorschriften für diese Situationen. Die Nutzungsbedingungen von OpenAI erlauben es dem Unternehmen, alle von den Nutzern und ChatGPT erzeugten Eingaben und Ausgaben zu verwenden, wobei personenbezogene Daten entfernt werden sollen. Es bestehen jedoch nach wie vor Bedenken hinsichtlich der Möglichkeit, dass private Unternehmensdaten durch geschickt gestaltete Eingabeaufforderungen extrahiert werden können.
Die Lösung: Selbstgehostete KI-Modelle
Eine Lösung für die Bedenken hinsichtlich der Datensicherheit und des Datenschutzes bei der Verwendung von KI-Modellen besteht darin, diese Modelle selbst zu hosten. Dies ermöglicht es Unternehmen, die Kontrolle über ihre Daten zu behalten und sicherzustellen, dass sie nicht in die falschen Hände geraten. Selbstgehostete KI-Modelle bieten eine sichere und vertrauenswürdige Möglichkeit, KI-Technologie zu nutzen, ohne sich um Datenschutz- und Cybersicherheitsbedenken sorgen zu müssen.
Wir werden dazu Ollama und Chatbox verwenden. Ollama ist ein optimiertes Tool zur lokalen Ausführung von Open-Source-Large Language Models (LLMs) wie Mistral und Llama 2. Chatbox ist eine Applikation, mit welcher die API Calls zu verschiedenen Modellen visualisiert werden können.
Das klingt zu stressig? Oder wäre besser als Hosted API? Nutzen Sie document-chat.com oder lassen sie sich in einem kostenlosen Erstgespräch von uns beraten .
Schritt 1: Ollama Download und Installation
Sie benötigen einen Server oder Rechner, der eine GPU besitzt. Leider muss dies eine NVidia GPU mit mindestens 8GB VRAM sein, oder ein Macbook mit der M-Chip Reihe. Die genauen Anforderungen finden Sie im Post: Was sind die Vorteile von selbst gehosteten KI Modellen?
TLDR version:
- https://ollama.com/download
ollama run llama2- ollama ist unter localhost:11434 erreichbar
Was ist Ollama?
Ollama ist ein optimiertes Tool zur lokalen Ausführung von Open-Source-Large Language Models (LLMs) wie Mistral und Llama 2. Ollama bündelt Modellgewichte, Konfigurationen und Datensätze zu einer einheitlichen Einheit, die von einem Modelfile verwaltet wird.
Das klingt zu stressig? Oder wäre besser als Hosted API? Nutzen Sie document-chat.com oder lassen sie sich in einem kostenlosen Erstgespräch von uns beraten .
Ollama unterstützt verschiedene LLMs, darunter LLaMA-2, uncensored LLaMA, CodeLLaMA, Falcon, Mistral, Vicuna-Modell, WizardCoder und Wizard uncensored.
Ollama unterstützt eine Vielzahl von Modellen, darunter Llama 2, Code Llama und andere. Es bündelt Modellgewichte, Konfigurationen und Daten in einer einzigen Einheit, die von einem Modelfile definiert wird.
Die fünf beliebtesten Modelle auf Ollama sind:
- llama2: Das beliebteste Modell für den allgemeinen Gebrauch.
- mistral: Das 7B-Modell von Mistral AI, aktualisiert auf Version 0.2.
- codellama: Ein großes Sprachmodell, das Texteingaben verwendet, um Code zu generieren und zu diskutieren.
- dolphin-mixtral: Ein uncensoredes, feinabgestimmtes Modell auf Basis des Mixtral MoE, das sich besonders für Codieraufgaben eignet.
- mistral-openorca: Mistral 7b, feinabgestimmt mit dem OpenOrca-Datensatz.
Ollama unterstützt außerdem die Erstellung und Verwendung von benutzerdefinierten Modellen. Sie können ein Modell mithilfe eines Modelfiles erstellen, in dem Sie die Modelldatei übergeben, verschiedene Schichten erstellen, die Gewichte schreiben und schließlich eine Erfolgsmeldung erhalten.
Einige der anderen Modelle, die auf Ollama verfügbar sind, umfassen:
- Llama2: Meta’s grundlegendes “Open Source”-Modell
- Mistral/Mixtral: Ein 7 Milliarden Parameter-Modell, das auf dem Mistral 7B-Modell mit dem OpenOrca-Datensatz feinabgestimmt ist.
- Llava: Ein multimodales Modell namens LLaVA (Large Language and Vision Assistant), das visuelle Eingaben interpretieren kann.
- CodeLlama: Ein Modell, das sowohl auf Code als auch auf natürliche Sprache in Englisch trainiert ist.
- DeepSeek Coder: Von Grund auf auf 87% Code und 13% natürlicher Sprache in Englisch trainiert.
- Meditron: Ein Open-Source-Medizinmodell, das aus Llama 2 ins medizinische Umfeld adaptiert wurde.
Installation und Einrichtung von Ollama
- Laden Sie Ollama von der offiziellen Website herunter.
- Nach dem Download ist der Installationsprozess einfach und ähnlich wie bei anderen Softwareinstallationen. Für macOS- und Linux-Benutzer kann Ollama mit einem Befehl installiert werden: curl https://ollama.ai/install.sh | sh.
- Sobald Ollama installiert ist, erstellt es eine API, über die das Modell bereitgestellt wird, sodass Benutzer direkt von ihrem lokalen Rechner aus mit dem Modell interagieren können.
- Ollama ist mit macOS und Linux kompatibel, die Unterstützung für Windows wird in Kürze verfügbar sein. Es kann leicht installiert und verwendet werden, um verschiedene Open-Source-Modelle lokal auszuführen. Das gewünschte Modell können Sie aus der Ollama-Bibliothek auswählen.
Ausführen von Modellen mit Ollama
Das Ausführen von Modellen mit Ollama ist ein einfacher Prozess. Benutzer können Modelle herunterladen und mit dem Befehl “run” in der Terminalanwendung ausführen. Wenn das Modell nicht installiert ist, lädt Ollama es automatisch herunter. Zum Beispiel, um das CodeLlama-Modell auszuführen, verwenden Sie den Befehl “ollama run codellama”.
Die Modelle werden in der ~/.ollama/models-Verzeichnisstruktur auf Ihrem lokalen Rechner gespeichert. Wenn Sie ein Modell mit dem Befehl “ollama pull” herunterladen, wird es im Verzeichnis ~/.ollama/models/manifests/registry.ollama.ai/library/
Ollama unterstützt auch die Verwendung des Modells über eine REST-API für Echtzeitinteraktionen.
Zusätzliche Features
Eine der einzigartigen Funktionen von Ollama ist die Unterstützung des Imports von GGUF- und GGML-Dateiformaten im Modelfile. Dies bedeutet, dass Sie ein Modell erstellen, darauf aufbauen, es iterativ verbessern und es hochladen können, um es mit anderen zu teilen, wenn Sie bereit sind.
Verfügbare Modelle
Ollama unterstützt eine Vielzahl von Modellen, und Sie finden eine Liste der verfügbaren Modelle auf der Ollama Model Library-Seite.
Zusammenfassend bietet Ollama eine benutzerfreundliche Umgebung zur lokalen Ausführung von Large Language Models. Es ist ein leistungsstarkes Tool für Entwickler, Forscher und KI-Enthusiasten, um die Möglichkeiten von LLMs zu nutzen.
Schritt 2: Ansteuern und Nutzen von Ollama mit der Chatbox GUI
Chatbox ist eine Applikation, mit welcher die API Calls zu verschiedenen Modellen visualisiert werden können.
Chatbox Installation
Besuchen Sie https://chatboxai.app und installieren Sie die App auf Ihrem Rechner.
Chatbox und Ollama verbinden
Wie im vorherigen Abschnitt erwähnt, ist unser lokales KI Modell nun unter localhost:11434 erreichbar. Chatbox bietet glücklicherweise eine einfache Möglichkeit, um mit Ollama zu interagieren. Dazu klickt man auf “Settings”, und wählt im “AI Model Provider” Ollama aus.
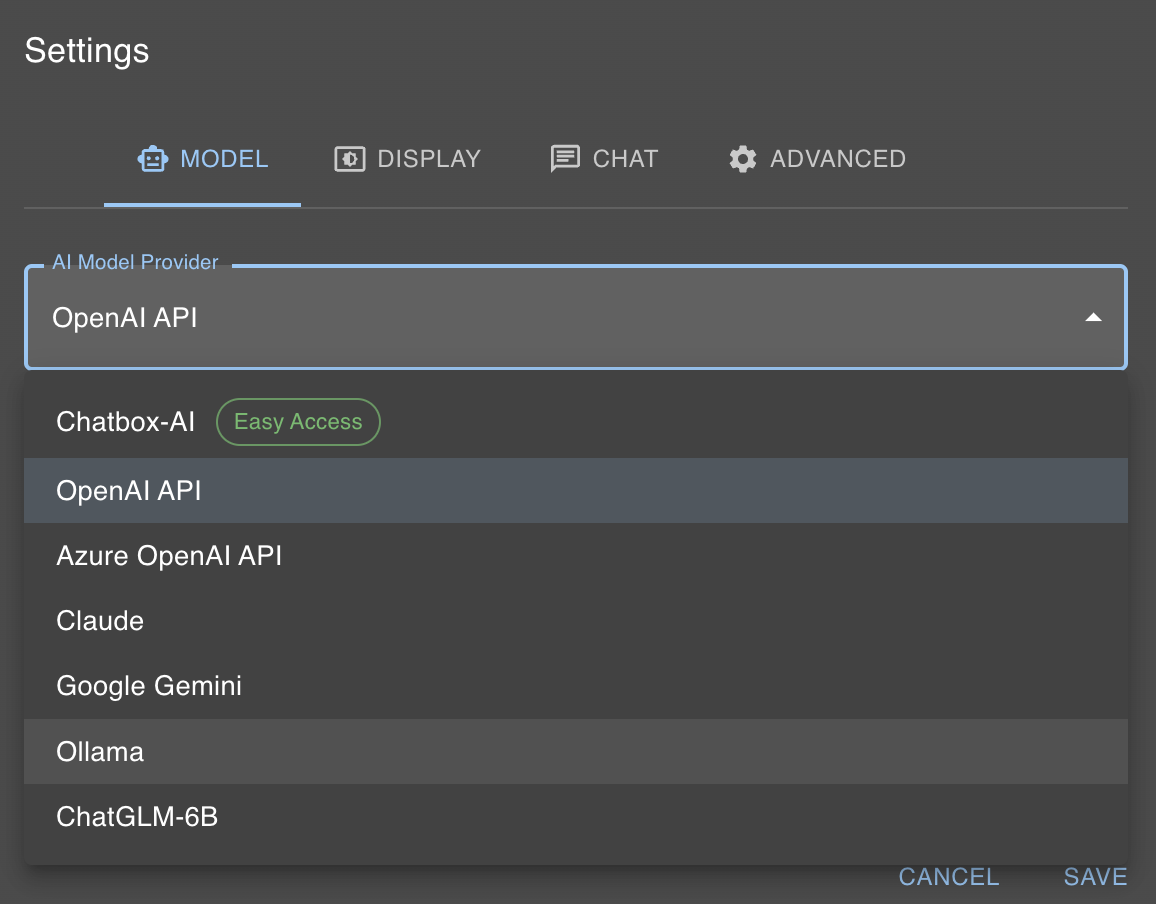
Danach muss man nur aus dem Modelldialog das Modell auswählen, welches man mit dem olama run Befehl ausgewählt hat, also in unserem Fall llama2.
Das klingt zu stressig? Oder wäre besser als Hosted API? Nutzen Sie document-chat.com oder lassen sie sich in einem kostenlosen Erstgespräch von uns beraten .